By Julia Stoyanovich (Assistant Professor of Computer Science at Drexel University) and Bill Howe (Associate Professor in the Information School at the University of Washington)
In August 2016, Julia Stoyanovich and Ellen P. Goodman spoke in this forum about the importance of bringing interpretability to the algorithmic transparency debate. They focused on algorithmic rankers, discussed the harms of opacity, and argued that the burden on making ranked outputs transparent rests with the producer of the ranking. They went on to propose a “nutritional label” for rankings called Ranking Facts.
In this post, Julia Stoyanovich and Bill Howe discuss their recent technical progress on bringing the idea of Ranking Facts to life, placing the nutritional label metaphor in the broader context of the ongoing algorithmic accountability and transparency debate.
In 2016, we began with a specific type of nutritional label that focuses on algorithmic rankers. We have since developed a Web-based Ranking Facts tool, which will be presented at the upcoming ACM SIGMOD 2018 conference.
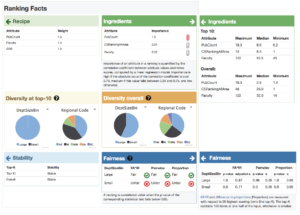
Figure 1: Ranking Facts on the CS departments dataset. The Ingredients widget (green) has been expanded to show the details of the attributes that strongly influence the ranking. The Fairness widget (blue) has been expanded to show details of the fairness computation.
Figure 1 presents Ranking Facts for CS department rankings, the same dataset as was used for illustration in our August 2016 post. The nutritional label was constructed automatically, and consists of a collection of visual widgets, each with an overview and a detailed view.
- Recipe widget succinctly describes the ranking algorithm. For example, for score-based ranker that uses a linear scoring formula to assign as score to each item, each attribute would be listed together with its weight.
- Ingredients widget lists attributes most material to the ranked outcome, in order of importance. For example, for a linear model, this list could present the attributes with the highest learned weights.
- Stability widget explains whether the ranking methodology is robust on this particular dataset – would small changes in the data, such as those due to uncertainty or noise, result in significant changes in the ranked order?
- Fairness and Diversity widgets quantify whether the ranked outcome exhibits parity (according to some measure – three such measures are presented in Figure 1), and whether the set of results is diverse with respect to one or several demographic characteristics.
What’s new about nutritional labels?
The database and cyberinfrastructure communities have been studying systems and standards for metadata, provenance, and transparency for decades. For example, the First Provenance Challenge in 2008 led to the creation of the Open Provenance Model that standardized years of previous efforts across multiple communities, We are now seeing renewed interest in these topics due to the proliferation of machine learning applications that use data opportunistically. Several projects are emerging that explore this concept, including Dataset Nutrition Label at the Berkman Klein Center at Harvard & the MIT Media Lab, Datasheets for Datasets, and some emerging work about Data Statements for NLP datasets from Bender and Friedman. In our work, we are interested in automating the creation of nutritional labels, for both datasets and models, and in providing open source tools for others to use in their projects.
Is a nutritional label simply an apt new name for an old idea? We think not! We see nutritional labels as a unifying metaphor that is responsive to changes in how data is being used today.
Datasets are now increasingly used to train models to make decisions once made by humans. In these automated systems, biases in the data are propagated and amplified with no human in the loop. The bias, and the effect of the bias on the quality of decisions made, is not easily detectable due to the relative opacity of the system. As we have seen time and time again, models will appear to work well, but will silently and dangerously reinforce discrimination. Worse, these models will legitimize the bias — “the computer said so.” So we are designing nutritional labels for data and models to respond specifically to the harms implied by these scenarios, in contrast to the more general concept of just “data about data.”
Use cases for nutritional labels: Enhancing data sharing in the public sector
Since we first began discussing nutritional labels in 2016, we’ve seen increased interest from the public sector in scenarios where data sharing is considered high-risk. Nutritional labels can be used to support data sharing, while mitigating some of the associated risks. Consider these examples:
Algorithmic transparency law in New York City
New York City recently passed a law requiring that a task force be put in place to survey the current use of “automated decision systems,” defined as “computerized implementations of algorithms, including those derived from machine learning or other data processing or artificial intelligence techniques, which are used to make or assist in making decisions,” in City agencies. The task force will develop a set of recommendations for enacting algorithmic transparency, which, as we argued in our testimony before the New York City Council Committee on Technology regarding Automated Processing of Data, cannot be achieved without data transparency. Nutritional labels can support data transparency and interpretability, surfacing the statistical properties of a dataset, the methodology that was used to produce it, and, ultimately, substantiating the “fitness for use” of a dataset in the context of a specific automated decision system or task.
Addressing the opioid epidemic
An effective response to the opioid epidemic requires coordination between at least three sectors: health care, criminal justice, and emergency housing. An optimization problem is to effectively, fairly and transparently assign resources, such as hospital rooms, jail cells, and shelter beds, to at-risk citizens. Yet, centralizing all data is disallowed by law, and solving the global optimization problem is therefore difficult. We’ve seen interest in nutritional labels to share the details of local resource allocation strategies, to help bootstrap a coordinated response without violating data sharing principles. In this case the nutritional labels are shared separately from the datasets themselves.
Mitigating urban homelessness
With the Bill and Melinda Gates Foundation, we are integrating data about homeless families from multiple government agencies and non-profits to understand how different pathways through the network of services affect outcomes. Ultimately, we are using machine learning to deliver prioritized recommendations to specific families. But the families and case workers need to understand how a particular recommendation was made, so they can in turn make an informed decision about whether to follow it. For example, income levels, substance abuse issues, or health issues may all affect the recommendation, but only the families themselves know whether the information is reliable.
Sharing transportation data
At the University of Washington, we are developing the Transportation Data Collaborative, an honest broker system that can provide reports and research to policy makers while maintaining security and privacy for sensitive information about companies and individuals. We are releasing nutritional labels for reports, models, and synthetic datasets that we produce to share known biases about the data and our methods of protecting privacy.
Properties of a nutritional label
To differentiate a nutritional label from more general forms of metadata, we articulate several properties:
- Comprehensible: The label is not a complete (and therefore overwhelming) history of every processing step applied to produce the result. This approach has its place and has been extensively studied in the literature on scientific workflows, but is unsuitable for the applications we target. The information on a nutritional label must be short, simple, and clear.
- Consultative: Nutritional labels should provide actionable information, rather than just descriptive metadata. For example, universities may invest in research to improve their ranking, or consumers may cancel unused credit card accounts to improve their credit score.
- Comparable: Nutritional labels enable comparisons between related products, implying a standard.
- Concrete: The label must contain more than just general statements about the source of the data; such statements do not provide sufficient information to make technical decisions on whether or not to use the data.
Data and models are chained together into complex automated pipelines — computational systems “consume” datasets at least as often as people do, and therefore also require nutritional labels! We articulate additional properties in this context:
- Computable: Although primarily intended for human consumption, nutritional labels should be machine-readable to enable specific applications: data discovery, integration, automated warnings of potential misuse.
- Composable: Datasets are frequently integrated to construct training data; the nutritional labels must be similarly integratable. In some situations, the composed label is simple to construct: the union of sources. In other cases, the biases may interact in complex ways: a group may be sufficiently represented in each source dataset, but underrepresented in their join.
- Concomitant: The label should be carried with the dataset; systems should be designed to propagate labels through processing steps, modifying the label as appropriate, and implementing the paradigm of transparency by design.
Going forward
We are interested in the application of nutritional labels at various stages in the data science lifecycle: Data scientists triage datasets for use to train their models; data practitioners inspect and validate trained models before deploying them in their domains; consumers review nutritional labels to understand how decisions that affect them were made and how to respond.
The software infrastructure implied by nutritional labels suggests a number of open questions for the computer science community: Under what circumstances can nutritional labels be generated automatically for a given dataset or model? Can we automatically detect and report potential misuse of datasets or models, given the information in a nutritional label? We’ve suggested that nutritional labels should be computable, composable, and concomitant — carried with the datasets to which they pertain; how can we design systems that accommodate these requirements?
We look forward to opening these discussions with the database community at two upcoming events: at ACM SIGMOD 2018, where we are organizing a special session on a technical research agenda in data ethics and responsible data management, and at VLDB 2018, where we will run a debate on data and algorithmic ethics.
Julia Stoyanovich, thanks so much for the post.Much thanks again. Really Cool.