By Julia Stoyanovich (Assistant Professor of Computer Science, Drexel University) and Ellen P. Goodman (Professor, Rutgers Law School)
ProPublica’s story on “machine bias” in an algorithm used for sentencing defendants amplified calls to make algorithms more transparent and accountable. It has never been more clear that algorithms are political (Gillespie) and embody contested choices (Crawford), and that these choices are largely obscured from public scrutiny (Pasquale and Citron). We see it in controversies over Facebook’s newsfeed, or Google’s search results, or Twitter’s trending topics. Policymakers are considering how to operationalize “algorithmic ethics” and scholars are calling for accountable algorithms (Kroll, et al.).
One kind of algorithm that is at once especially obscure, powerful, and common is the ranking algorithm (Diakopoulos). Algorithms rank individuals to determine credit worthiness, desirability for college admissions and employment, and compatibility as dating partners. They encode ideas of what counts as the best schools, neighborhoods, and technologies. Despite their importance, we actually can know very little about why this person was ranked higher than another in a dating app, or why this school has a better rank than that one. This is true even if we have access to the ranking algorithm, for example, if we have complete knowledge about the factors used by the ranker and their relative weights, as is the case for US News ranking of colleges. In this blog post, we argue that syntactic transparency, wherein the rules of operation of an algorithm are more or less apparent, or even fully disclosed, still leaves stakeholders in the dark: those who are ranked, those who use the rankings, and the public whose world the rankings may shape.
Using algorithmic rankers as an example, we argue that syntactic transparency alone will not lead to true algorithmic accountability (Angwin). This is true even if the complete input data is publicly available. We advocate instead for interpretability, which rests on making explicit the interactions between the program and the data on which it acts. An interpretable algorithm allows stakeholders to understand the outcomes, not merely the process by which outcomes were produced.
Opacity in Algorithmic Rankers
Algorithmic rankers take as input a database of items and produce a ranked list of items as output. The relative ranking of the items may be computed based on an explicitly provided scoring function. Or the ranking function may be learned, using learning-to-rank methods that are deployed extensively in information retrieval and recommender systems.
The simplest kind of a ranker is a score-based ranker, which applies a scoring function independently to each item and then sorts the items on their scores. Many of these rankers use monotone aggregation scoring functions, such as weighted sums of attribute values with non-negative weights. In the very simplest case, the score of an item is computed by sorting on the value of just one attribute, i.e., by setting the weight of that attribute to 1 and of all other attributes to 0.
This is illustrated in our running example in Table 1, which gives a ranking of 51 computer science departments as per csrankings.org (CSR). We augmented the data with several attributes from the assessment of research-doctorate programs by the National Research Council (NRC) to illustrate some points. Source of an attribute (CSR or NRC) is listed next to the attribute name. We recognize that the augmented CS rankings are already syntactically transparent. What’s more, they provide the entire data set. We use them for illustrative purposes.
Table 1: A ranking of Computer Science departments per csrankings.org, with additional attributes from the NRC assessment dataset. Here, the average count computes the geometric mean of the adjusted number of publications in each area by institution, faculty is the number of faculty in the department, pubs is the average number of publications per faculty (2000-2006) , GRE is the average GRE scores (2004-2006). Departments are ranked by average count.
| Rank (CSR) | Name | Average Count (CSR) | Faculty (CSR) | Pubs (NRC) | GRE (NRC) |
|---|---|---|---|---|---|
| 1 | Carnegie Mellon University | 18.3 | 122 | 2 | 791 |
| 2 | Massachusetts Institute of Technology | 15 | 64 | 3 | 772 |
| 3 | Stanford University | 14.3 | 55 | 5 | 800 |
| 4 | University of California–Berkeley | 11.4 | 50 | 3 | 789 |
| 5 | University of Illinois–Urbana-Champaign | 10.5 | 55 | 3 | 772 |
| full table | |||||
| 45 | Yale University | 1.5 | 18 | 2 | 800 |
| 45 | University of Virginia | 1.5 | 18 | 2 | 789 |
| 45 | University of Rochester | 1.5 | 18 | 3 | 786 |
| 48 | Arizona State University | 1.4 | 14 | 2 | 787 |
| 48 | University of Arizona | 1.4 | 18 | 2 | 784 |
| 48 | Virginia Polytechnic Institute and State University | 1.4 | 32 | 1 | 780 |
| 48 | Washington University in St. Louis | 1.4 | 17 | 2 | 790 |
Ranked results are difficult for people to interpret, whether a ranking is computed explicitly or learned, whether the method (e.g., the scoring function or, more generally, the model) is known or unknown, and whether the user can access the entire output or only the highest-ranked items (the top-k). There are several sources of this opacity, illustrated below for score-based rankers.
Sources of Opacity
Source 1: The scoring formula alone does not indicate the relative rank of an item. Rankings are, by definition, relative, while scores are absolute. Knowing how the score of an item is computed says little about the outcome — the position of a particular item in the ranking, relative to other items. Is 10.5 a high score or a low score? That depends on how 10.5 compares to the scores of other items, for example to the highest attainable score and to the highest score of some actual item in the input. In our example in Table 1 this kind of opacity is mitigated because there is both syntactic transparency (the scoring formula is known) and the input is public.
Source 2: The weight of an attribute in the scoring formula does not determine its impact on the outcome. Consider again the example in Table 1, and suppose that we first normalize the values of the attributes, and then compute the score of each department by summing up the values of faculty (with weight 0.2), average count (with weight 0.3) and GRE (with weight 0.5). According to this scoring method, the size of the department (faculty) is the least important factor. Yet, it will be the deciding factor that sets apart top-ranked departments from those in lower ranks, both because the value of this attribute changes most dramatically in the data, and because it correlates with average count (in effect, double-counting). In contrast, GRE is syntactically the most important factor in the formula, yet in this dataset it has very close values for all items, and so has limited actual effect on the ranking.
Source 3: The ranking output may be unstable. A ranking may be unstable because of the scores generated on a particular dataset. An example would be tied scores, where the tie is not reflected in the ranking. In this case, the choice of any particular rank order is arbitrary. Moreover, unless raw scores are disclosed, the user has no information about the magnitude of the difference in scores between items that appear in consecutive ranks. In Table 1, CMU (18.3) has a much higher score than the immediately following MIT (15). This is in contrast to, e.g., UIUC (10.5, rank 5) and UW (10.3, rank 6), which are nearly tied. The difference in scores between distinct adjacent ranks decreases dramatically as we move down the list: it is at most 0.3, and usually 0.1, for departments in ranks 16 through 48. CSRankings’ syntactic transparency (disclosing its ranking method to the user) and accessible data allow us to see the instability, but this is unusual.
Source 4: The ranking methodology may be unstable. The scoring function may produce vastly different rankings with small changes in attribute weights. This is difficult to detect even with syntactic transparency, and even if the data is public. Malcolm Gladwell discusses this issue and gives compelling examples in his 2011 piece, The Order of Things. In our example in Table 1, a scoring function that is based on a combination of pubs and GRE would be unstable, because the values of these attributes are both very close for many of the items and induce different rankings, and so prioritizing one attribute over the other slightly would cause significant re-shuffling.
The opacity concerns described here are all due to the interaction between the scoring formula (or, more generally, an a priori postulated model) and the actual dataset being ranked. In a recent paper, one of us observed that structured datasets show rich correlations between item attributes in the presence of ranking, and that such correlations are often local (i.e., are present in some parts of the dataset but not in others). To be clear, this kind of opacity is present whether or not there is syntactic transparency.
Harms of Opacity
Opacity in algorithmic rankers can lead to four types of harms:
(1) Due process / fairness. The subjects of the ranking cannot have confidence that their ranking is meaningful or correct, or that they have been treated like similarly situated subjects. Syntactic transparency helps with this but it will not solve the problem entirely, especially when people cannot interpret how weighted factors have impacted the outcome (Source 2 above).
(2) Hidden normative commitments. A ranking formula implements some vision of the “good.” Unless the public knows what factors were chosen and why, and with what weights assigned to each, it cannot assess the compatibility of this vision with other norms. Even where the formula is disclosed, real public accountability requires information about whether the outcomes are stable, whether the attribute weights are meaningful, and whether the outcomes are ultimately validated against the chosen norms. Did the vendor evaluate the actual effect of the features that are postulated as important by the scoring / ranking mode? Did the vendor take steps to compensate for mutually-reinforcing correlated inputs, and for possibly discriminatory inputs? Was stability of the ranker interrogated on real or realistic inputs? This kind of transparency around validation is important for both learning algorithms which operate according to rules that are constantly in flux and responsive to shifting data inputs, and for simpler score-based rankers that are likewise sensitive to the data.
(3) Interpretability. Especially where ranking algorithms are performing a public function (e.g., allocation of public resources or organ donations) or directly shaping the public sphere (e.g., ranking politicians), political legitimacy requires that the public be able to interpret algorithmic outcomes in a meaningful way. At the very least, they should know the degree to which the algorithm has produced robust results that improve upon a random ordering of the items (a ranking-specific confidence measure). In the absence of interpretability, there is a threat to public trust and to democratic participation, raising the dangers of an algocracy (Danaher) – rule by incontestable algorithms.
(4) Meta-methodological assessment. Following on from the interpretability concerns is a meta question about whether a ranking algorithm is the appropriate method for shaping decisions. There are simply some domains, and some instances of datasets, in which rank order is not appropriate. For example, if there are very many ties or near-ties induced by the scoring function, or if the ranking is too unstable, it may be better to present data through an alternative mechanism such as clustering. More fundamentally, we should question the use of an algorithmic process if its effects are not meaningful or if it cannot be explained. In order to understand whether the ranking methodology is valid, as a first order question, the algorithmic process needs to be interpretable.
The Possibility of Knowing
Recent scholarship on the issue of algorithmic accountability has devalued transparency in favor of verification. The claim is that because algorithmic processes are protean and extremely complex (due to machine learning) or secret (due to trade secrets or privacy concerns), we need to rely on retrospective checks to ensure that the algorithm is performing as promised. Among these checks would be cryptographic techniques like zero knowledge proofs (Kroll, et al.) to confirm particular features, audits (Sandvig) to assess performance, or reverse engineering (Perel and Elkin-Koren) to test cases.
These are valid methods of interrogation, but we do not want to give up on disclosure. Retrospective testing puts a significant burden on users. Proofs are useful only when you know what you are looking for. Reverse engineering with test cases can lead to confirmation bias. All these techniques put the burden of inquiry exclusively on individuals for whom interrogation may be expensive and ultimately fruitless. The burden instead should fall more squarely on the least cost avoider, which will be the vendor who is in a better position to reveal how the algorithm works (even if only partially). What if food manufacturers resisted disclosing ingredients or nutritional values, and instead we were put to the trouble of testing their products or asking them to prove the absence of a substance? That kind of disclosure by verification is very different from having a nutritional label.
What would it take to provide the equivalent of a nutritional label for the process and the outputs of algorithmic rankers? What suffices as an appropriate and feasible explanation depends on the target audience.
For an individual being ranked, a useful description would explain his specific ranked outcome and suggest ways to improve the outcome. What changes can NYU CS make to improve its ranking? Why is the NYU CS department ranked 24? Which attributes make this department perform worse than those ranked higher? As we argued above, the answers to these questions depend on the interaction between the ranking method and the dataset over which the ranker operates. When working with data that is not public (e.g., involving credit or medical information about individuals), an explanation mechanism of this kind must be mindful of any privacy considerations. Individually-responsive disclosures could be offered in a widget that allows ranked entities to experiment with the results by changing the inputs.
An individual consumer of a ranked output would benefit from a concise and intuitive description of the properties of the ranking. Based on this explanation, users will get a glimpse of, e.g., the diversity (or lack thereof) that the ranking exhibits in terms of attribute values. Both attributes that comprise the scoring function, if known (or, more generally, features that make part of the model), and attributes that co-occur or even correlate with the scoring attributes, can be described explicitly. In our example in Table 1, a useful explanation may be that a ranking on average count will over-represent large departments (with many faculty) at the top of the list, while GRE does not strongly influence rank.
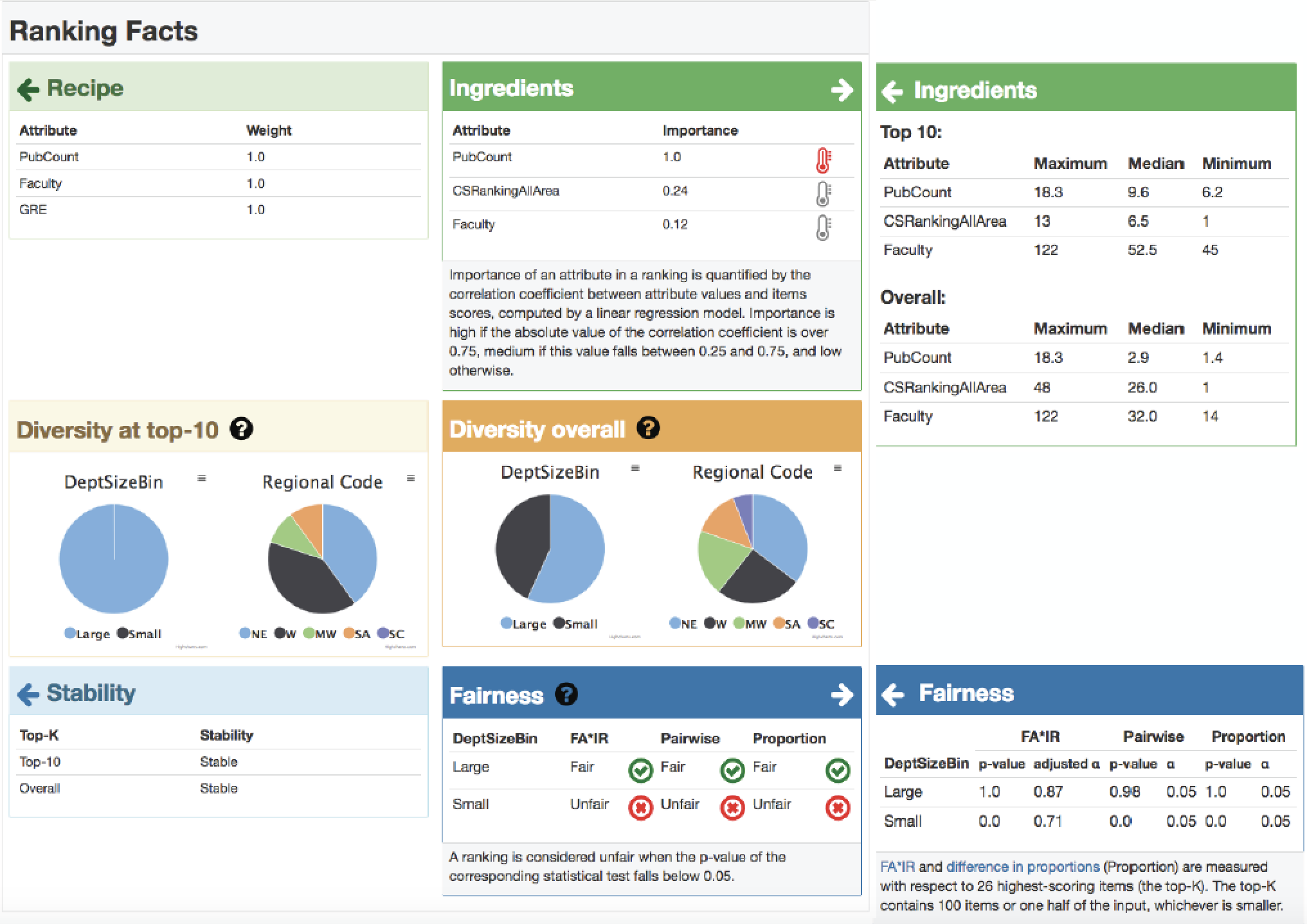
Figure 1: A hypothetical Ranking Facts label.
Figure 1 presents a hypothetical “nutritional label” for rankings, using the augmented CSRankings in Table 1 as input. Inspired by Nutrition Facts, our Ranking Facts label is aimed at the consumer, such as a prospective CS program applicant, and addresses three of the four opacity sources described above: relativity, impact, and output stability. We do not address methodological stability in the label. How this dimension should be quantified and presented to the user is an open technical problem.
The Ranking Facts show how the properties of the 10 highest-ranked items compare to the entire dataset (Relativity), making explicit cases where the ranges of values, and the median value, are different at the top-10 vs. overall (median is marked with red triangles for faculty size and average publication count). The label lists the attributes that have most impact on the ranking (Impact), presents the scoring formula (if known), and explains which attributes correlate with the computed score. Finally, the label graphically shows the distribution of scores (Stability), explaining that scores differ significantly up to top-10 but are nearly indistinguishable in later positions.
Something like the Rankings Facts makes the process and outcome of algorithmic ranking interpretable for consumers, and reduces the likelihood of opacity harms, discussed above. Beyond Ranking Facts, it is important to develop Interpretability tools that enable vendors to design fair, meaningful and stable ranking processes, and that support external auditing. Promising technical directions include, e.g., quantifying the influence of various features on the outcome under different assumptions about availability of data and code, and investigating whether provenance techniques can be used to generate explanations.