By Chong Xiang and Prateek Mittal
Thanks to the stunning advancement of Machine Learning (ML) technologies, ML models are increasingly being used in critical societal contexts — such as in the courtroom, where judges look to ML models to determine whether a defendant is a flight risk, and in autonomous driving, where driverless vehicles are operating in city downtowns. However, despite the advantages, ML models are also vulnerable to adversarial attacks, which can be harmful to society. For example, an adversary against image classifiers can augment an image with an adversarial pixel patch to induce model misclassification. Such attacks raise questions about the reliability of critical ML systems and have motivated the design of trustworthy ML models.
In this 2-part post on trustworthy machine learning design, we will focus on ML models for image classification and discuss how to protect them against adversarial patch attacks. We will first introduce the concept of adversarial patches and then present two of our defense algorithms: PatchGuard in Part 1 and PatchCleanser in Part 2.
Adversarial Patch Attacks: A Threat in the Physical World
The adversarial patch attack, first proposed by Brown et al., targets image recognition models (e.g., image classifiers). The attacker aims to overlay an image with a carefully generated adversarial pixel patch to induce models’ incorrect predictions (e.g., misclassification). Below is a visual example of the adversarial patch attack against traffic sign recognition models: after attaching an adversarial patch, the model prediction changes from “stop sign” to “speed limit 80 sign” incorrectly.

Notably, this attack can be realized in the physical world. An attacker can print and attach an adversarial patch to a physical object or scene. Any image taken from this scene then becomes an adversarial image. Just imagine that a malicious sticker attached to a stop sign confuses the perception system of an autonomous vehicle and eventually leads to a serious accident! This threat to the physical world motivates us to study mitigation techniques against adversarial patch attacks.
Unfortunately, security is never easy. An attacker only needs to find one strategy to break the entire system while a defender has to defeat as many attack strategies as possible.
In the remainder of this post, we discuss how to make an image classification model as secure as possible: able to make correct and robust predictions against attackers who know everything about the defense and who might attempt to use an adversarial patch at any image location and with any malicious content.
This as-robust-as-possible notion is referred to as provable, or certifiable, robustness in the literature. We refer interested readers to the PatchGuard and PatchCleanser papers for its formal definitions and security guarantees
PatchGuard: A Defense Framework Using Small Receptive Field + Secure Aggregation
PatchGuard is a defense framework for certifiably robust image classification against adversarial patch attacks. Its design is motivated by the following question:
How can we ensure that the model prediction is not hijacked by a small localized patch?
We propose a two-step defense strategy: (1) small receptive fields and (2) secure aggregation. The use of small receptive fields limits the number of corrupted features, and secure aggregation on a partially corrupted feature map allows us to make robust final predictions.
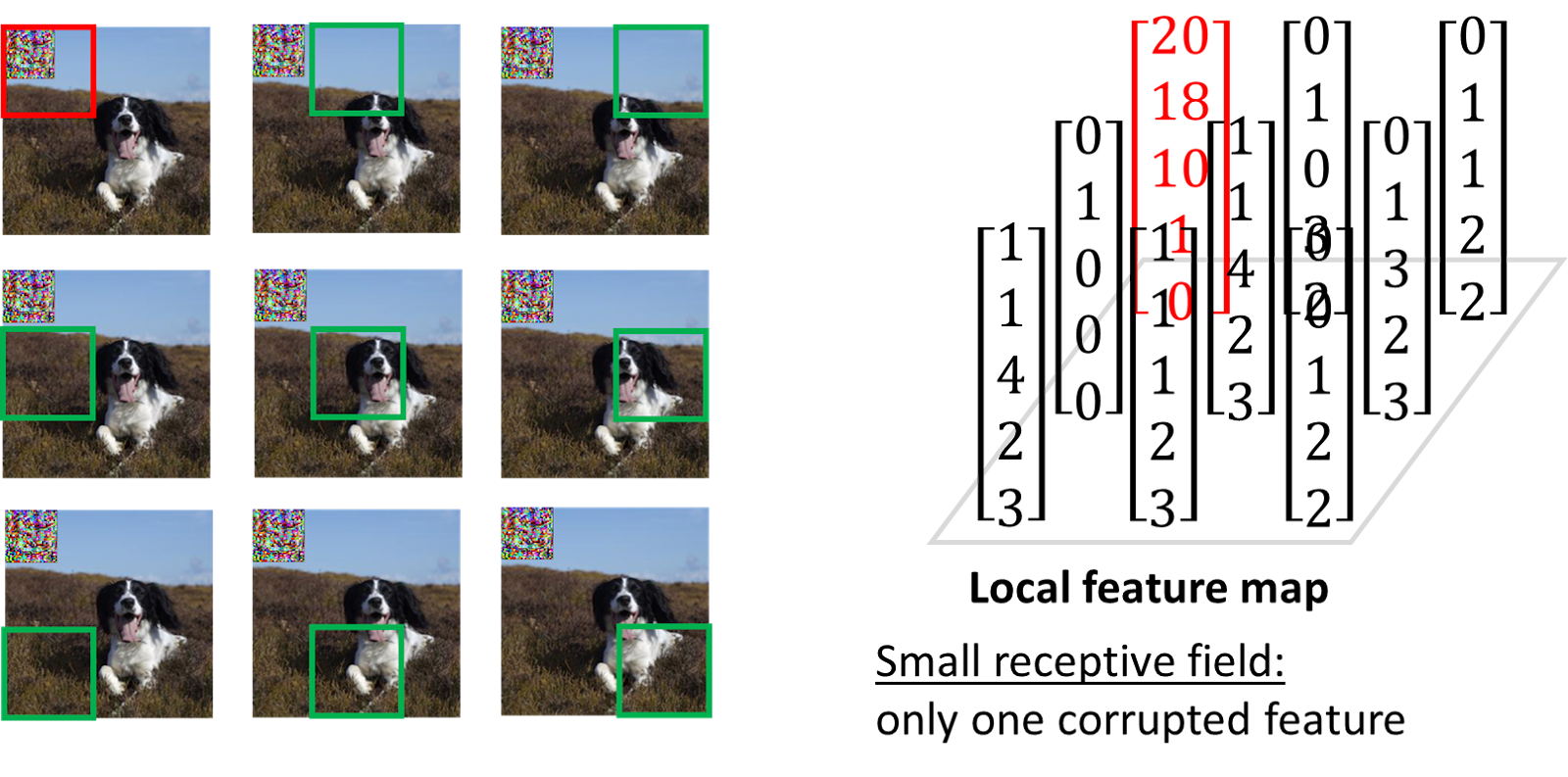
Step 1: Small Receptive Fields. The receptive field of an image classifier (e.g., CNN) is the region of the input image that a particular feature looks at (or is influenced by). The model prediction is based on the aggregation of features extracted from different regions of an image. By using a small receptive field, we can ensure that only a limited number of features “see” the adversarial patch.
The example below illustrates that the adversarial patch can only corrupt one feature — the red vector on the right – when we use a model with small receptive fields, marked with red and green boxes over the images.
.
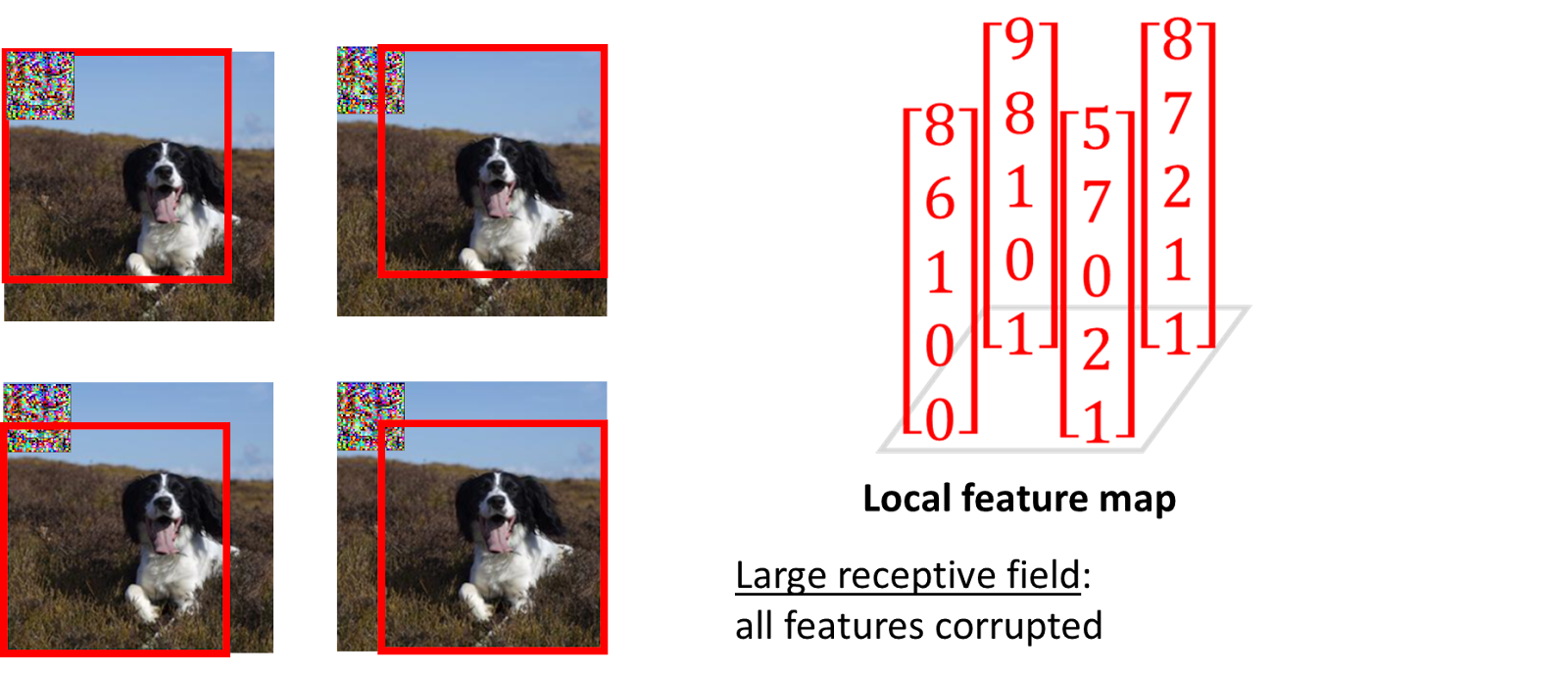
We provide another example below for large receptive fields. The adversarial pixels appear in the receptive fields – the area inside the red boxes – of all four features and lead to a completely corrupted feature map, making it nearly impossible to recover the correct prediction.
Step 2: Secure Aggregation. The use of small receptive fields limits the number of corrupted features and translates the defense into a secure aggregation problem: how can we make a robust prediction based on a partially corrupted feature map? Here, we can use any off-the-shelf robust statistics techniques (e.g., clipping and median) for feature aggregation.
In our paper, we further propose a more powerful secure aggregation technique named robust masking. Its design intuition is to identify and remove abnormally large features. This mechanism introduces a dilemma for the attacker. If the attacker wants to launch a successful attack, it needs to either introduce large malicious feature values that will be removed by our defense, or use small feature values that can evade the masking operation, but are not malicious enough to cause misclassification.
This dilemma further allows us to analyze the defense robustness. For example, if we consider a square patch that occupies 1% of image pixels, we can calculate the largest number of corrupted features and quantitatively reason about the worst-case feature corruption (details in the paper). Our evaluation shows that, for 89.0% of images in the test set of the ImageNette dataset (a 10-class subset of the ImageNet dataset), our defense can always make correct predictions, even when the attacker has full access to our defense setup and can place a 1%-pixel square patch at any image location and with any malicious content. We note that the result of 89.0% is rigorously proved and certified in our paper, giving the defense theoretical and formal security guarantees.
Furthermore, PatchGuard is also scalable to more challenging datasets like ImageNet. We can achieve certified robustness for 32.2% of ImageNet test images, against a 1%-pixel square patch. Note that the ImageNet dataset contains images from 1000 different categories, which means that an image classifier that makes random predictions can only correctly classify roughly 1/1000=0.1% of images.
Takeaways
The high-level contribution of PatchGuard is a two-step defense framework: small receptive field and secure aggregation. This simple approach turns out to be a very powerful strategy: the PatchGuard framework subsumes most of the concurrent (Clipped BagNet, De-randomized Smoothing) and follow-up works (BagCert, Randomized Cropping, PatchGuard++, ScaleCert, Smoothed ViT, ECViT). We refer interested readers to our robustness leaderboard to learn more about state-of-the-art defense performance.
Conclusion
In this post, we discussed the threat of adversarial patch attacks and presented our PatchGuard defense algorithm (small receptive field and secure aggregation). This defense example demonstrates one of our efforts toward building trustworthy ML models for critical societal applications such as autonomous driving.
In the second part of this two-part post, we will present PatchCleanser — our second example for designing robust ML algorithms.