By Chong Xiang and Prateek Mittal
In our previous post, we discussed adversarial patch attacks and presented our first defense algorithm PatchGuard. The PatchGuard framework (small receptive field + secure aggregation) has become the most popular defense strategy over the past year, subsuming a long list of defense instances (Clipped BagNet, De-randomized Smoothing, BagCert, Randomized Cropping, PatchGuard++, ScaleCert, Smoothed ViT, ECViT). In this post, we will present a different way of building robust image classification models: PatchCleanser. Instead of using small receptive fields to suppress the adversarial effect, PatchCleanser directly masks out adversarial pixels in the input image. This design makes PatchCleanser compatible with any high-performance image classifiers and achieve state-of-the-art defense performance.
PatchCleanser: Removing the Dependency on Small Receptive Fields
The limitation of small receptive fields. We have seen the small receptive field plays an important role in PatchGuard: it limits the number of corrupted features and lays a foundation for robustness. However, the small receptive field also limits the information received by each feature; as a result, it hurts the clean model performance (when there is no attack). For example, the PatchGuard models (BagNet+robust masking) can only have a 55%-60% clean accuracy on the ImageNet dataset while state-of-the-art undefended models, which all have large receptive fields, can achieve an accuracy of 80%-90%.

This huge drop in clean accuracy discourages the real-world deployment of PatchGuard-style defenses. A natural question to ask is:
Can we achieve strong robustness without the use of small receptive fields?
YES, we can. We propose PatchCleanser with an image-space pixel masking strategy to make the defense compatible with any state-of-the-art image classification model (with larger receptive fields).
A pixel-masking defense strategy. The high-level idea of PatchCleanser is to apply pixel masks to the input image and evaluate model predictions on masked images. If a mask removes the entire patch, the attacker has no influence over the classification, and thus any image classifier can make an accurate prediction on the masked image. However, the challenge is: how can we mask out the patch, especially when the patch location is unknown?
Pixel masking: the first attempt. A naive approach is to choose a mask and apply it to all possible image locations. If the mask is large enough to cover the entire patch, then at least one mask location can remove all adversarial pixels.
We provide a simplified visualization below. When we apply masks to an adversarial image (top of the figure), the model prediction is correct as “dog” when the mask removes the patch at the upper left corner. Meanwhile, the predictions on other masked images are incorrect since they are influenced by the adversarial patch — we see a prediction disagreement among different masked images. On the other hand, when we consider a clean image (bottom of the figure), the model predictions usually agree on the correct label since both we and the classifier can easily recognize the partially occluded dog.

Based on these observations, we can use the disagreement in one-mask predictions to detect a patch attack; a similar strategy is used by the Minority Reports defense, which takes inconsistency in the prediction voting grid as an attack indicator. However, can we recover the correct prediction label instead of merely detecting an attack? Or equivalently, how can we know which mask removes the entire patch? Which class label should an image classifier trust — dog, cat, or fox?
Pixel masking: the second attempt. The solution turns out to be super simple: we can perform a second round of masking on the one-masked images (see visual examples below). If the first-round mask already removes the patch (top of the figure), then our second-round masking is applied to a “clean” image, and thus all two-mask predictions will have a unanimous agreement. On the other hand, if the patch is not removed by the first-round mask (bottom of the figure), the image is still “adversarial”. We will then see a disagreement in two-mask predictions; we shall not trust the prediction labels.

In our PatchCleanser paper, we further discuss how to generate a mask set such that at least one mask can remove the entire patch regardless of the patch location. We further prove that if the model predictions on all possible two-masked images are correct, PatchCleanser can always make correct predictions.
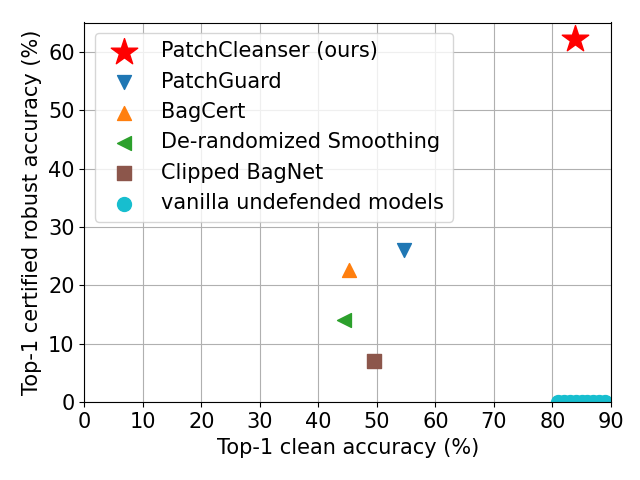
PatchCleanser performance. In the figure below, we plot the defense performance on the 1000-class ImageNet dataset (against a 2%-pixel square patch anywhere on the image). We can see that PatchCleanser significantly outperforms prior works (which are all PatchGuard-style defenses with small receptive fields). Notably, (1) the certified robust accuracy of PatchCleanser (62.1%) is even higher than the clean accuracy of all prior defenses, and (2) the clean accuracy of PatchCleanser (83.9%) is similar to vanilla undefended models! These results further demonstrate the strength of defenses that are compatible with any state-of-the-art classification models (with large receptive fields).
(certified robust accuracy is a provable lower bound on model robust accuracy; see the PatchCleanser paper for more details)
Takeaways. In PatchCleanser, we demonstrate that small receptive fields are not necessary for strong robustness. We design an image-space pixel masking strategy that is compatible with any image classifier. The compatibility allows us to use state-of-the-art image classifiers and achieves significant improvements over prior works.
Conclusion: Using Logical Reasoning for Building Trustworthy ML systems
In the era of big data, we have been amazed at the power of statistical reasoning/learning: an AI model can automatically extract useful information from a large amount of data and significantly outperforms manually designed models (e.g., hand-crafted features). However, these learned models can have unexpected behaviors when encountered with “adversarial examples” and thus lacks reliability for security-critical applications. In our posts, we demonstrate that we can additionally apply logical reasoning to statistically learned models to achieve strong robustness. We believe the combination of logical and statistical reasoning is a promising and important direction for building trustworthy ML systems.
Additional Reading
- Paper list for localized adversarial patch research [link]
- Leaderboard for certifiable robustness against adversarial patch attacks [link]
- PatchGuard [paper and presentation] [code on GitHub]
- PatchCleanser [paper and presentation] [code on GitHub]