[This is the fourth in a series of posts. The other posts in the series are here: 1 2 3.]
In the previous post, we did a deep dive into chess ratings, as an example of a system to measure a certain type of intelligence. One of the takeaways was that the process of numerically measuring intelligence, in order to support claims such as “intelligence is increasing exponentially”, is fraught with complexity.
Today I want to wrap up the discussion of quantifying AI intelligence by turning to a broad class of AI systems whose performance is measured as an error rate, that is, the percentage of examples from population for which the system gives a wrong answer. These applications include facial recognition, image recognition, and so on.
For these sorts of problems, the error rate tends to change over time as shown on this graph:
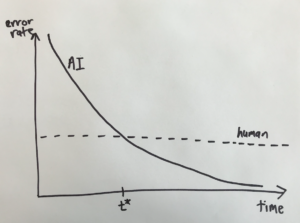
The human error rate doesn’t change, but the error rate for the AI system tends to fall exponentially, crossing the human error rate at a time we’ll call t*, and continuing to fall after that.
How does this reduction in error rate translate into outcomes? We can get a feel for this using a simple model, where a wrong answer is worth W and a right answer is worth R, with R>W, naturally.
In this model, the value created per decision changes over time as shown in this graph:
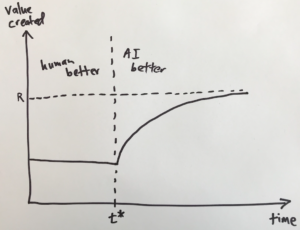
Before t*, humans perform better, and the value is unchanged. At t*, AI becomes better and the graph takes a sharp turn upward. After that, the growth slows as the value approaches its asymptote of R.
This graph has several interesting attributes. First, AI doesn’t help at all until t*, when it catches up with people. Second, the growth rate of value (i.e., the slope of the curve) is zero while humans are better, then it lurches upward at t*, then the growth rate falls exponentially back to zero. And third, most of the improvement that AI can provide will be realized in a fairly short period after t*.
Viewed over a long time-frame, this graph looks a lot like a step function: the effect of AI is a sudden step up in the value created for this task. The step happens in a brief interval after AI passes human performance. Before and after that interval, the value doesn’t change much at all.
Of course, this simple model can’t be the whole story. Perhaps a better solution to this task enables other tasks to be done more effectively, multiplying the improvement. Perhaps people consume more of this tasks’s output because it is better. For these and other reasons, things will probably be somewhat better than this model predicts. But the model is still a long way from establishing that any kind of intelligence explosion or Singularity is going to happen.
Next time, we’ll dive into the question of how different AI tasks are connected, and how to think about the Singularity in a world where task-specific AI is all we have.
nice analysis! yes the mere word “singularity” is probably misleading. but lots of terms are like that. its evocative. did you hear about chollets great essay on subj? cited in following. do feel also that alphazero is a gamechanger pointing toward AGI underpinnings.
this is a new, innovative, semicomprehensive AGI theory. comments welcome.
https://vzn1.wordpress.com/2018/01/04/secret-blueprint-path-to-agi-novelty-detection-seeking/
Viewed at a distance, the value graph does approximate a step function: from “smart-enough to be useful” up to “nearly perfect” (for some definition of perfect). Isn’t a step function a kind of singularity?
But I guess I’m losing sight of your thesis. In the first post, you defined the Singularity as, “that notional future time when machine intelligence explodes in capability, changing human life forever.” Isn’t a step function where AI goes from being less useful than human intelligence to approaching perfection exactly that?
If it were only in a limited number of fields, say Chess and recognizing pictures of cats, then, sure, it wouldn’t be a society-changing event. But we’ve seen that the tech that’s enabling these recent strides forward in toy domains is surprisingly general and already being repurposed to very different problem spaces.
So perhaps your argument is that AI won’t be able to scale out horizontally across all (more nearly all) tasks that currently require human intelligence (let alone a host of tasks we haven’t even thought of yet). But I haven’t (yet) seen that argument. Or maybe you believe that this won’t be an irreversible, society-changing event?
The argument so far seems (to me) to be that there’s always a limit that can only be approached asymptotically, and thus you can’t technically have an endlessly growing explosion. But if it’s a sudden, finite step-function-like change that inverts the HI and AI in a way that makes it unlikely the humans could ever catch up, isn’t that effectively a point in time that changes human life forever?
The thesis that there’s an asymptotic limit to self-improvement must rationalize how the evidence we’ve seen in bounded problem domains relates to intelligence in general. I don’t see a way to do this without arguing that the maximum intelligence an entity can achieve is also meaningfully bounded in the context of this discussion.
This oversimplifies things. There are very few “best humans”, e.g. Chess Players. Are you talking 6 sigma super expert or average human?
Also, AI’s errors might be DIFFERENT than humans. Consider if Humans err by giving false negatives, and AI errs by giving false positives. And they aren’t symmetric, consider drug testing or finding someone guilty of a capital crime. It is also possible to extract value by focusing on the cases where AI and humans give different answers and then learn what the correct one is.
Also what if the “right” answers aren’t acceptable. What if we ask “Which women are happiest”, and AI (assume correctly) says those who marry early and become mothers. What if AI gives racist answers that are statistically correct? Even something as simple as a Credit score. Normally we would let a human reexamine things based on details AI wouldn’t look at. AI is completely AMORAL – so when we ask the question, it will be the technically correct one, but one we may not want to hear.
We already have a problem with opaque and unavailable algorithms where the decision tree and weighting of various factors could be made visible. With AI, we are pure utilitiarian, but have no real idea how it is coming to its conclusions. Even humans I can try finding evidence of unconscious bias which might give wrong answers.
In a real recent case, there were demographic differences in bail being allowed or denied to people based on one of these big-data programs. Neighborhoods are assigned more or fewer police based on them. The authors say it is all based on data, won’t show the algorithms, but are generally correct. What happens if AI determines far more blacks should be denied bail than whites? More men than women? Or vice versa. And worse, what if the AI is accurately determining who will skip and who will appear? We need to ask these questions, and I’m using a specific real and controversial case to make it clear, before implementing AI broadly.
I should also note for decisions about humans, AI will need data – the kind of panopticon data Google and Facebook and other data brokers collect, at least in the US. This is another problem. Do I have the right to be a “blank” and not to be discriminated because I don’t have a Facebook, Twitter, Search, or other profile?
Perhaps a more ontological weighted ANOVA System is more accurate then defining equally weighted errors. Chessbase currently uses an error rate statistic in GM games. If white was accurate 70 percent of moves to blacks 55 percent this is helpful but is only instructive to developing pure efficiency.
You could have not written this and the world would be exactly the same. It does not contribute to the understanding of the concept of technicalogical acceleration and instead looks for simplistic explainations of complex phenomenon in order to nick pick and be contrarian instead of being scientifically objective.
A better title might be: “An overly simplified misunderstanding of technological progress… examining a contrarian’s myopic viewpoint designed to build up his deflated sense of self worth.”
Can we please focus on the arguments rather than the people making them?
Although I don’t (currently) agree with the position Mr. Felton is taking, I appreciate that he’s sharing his perspective and giving us a forum to debate the ideas. I find that learning how others view a topic helps me better formulate my own ideas.