Today at the Usenix Security Symposium a group of researchers from UC San Diego and the University of Michigan will present a paper demonstrating flaws in a full-body scaning machine that was used at many U.S. airports. In this post I’ll summarize their findings and discuss the security and policy implications.
(The researchers offer a page with images, a FAQ, etc.)
The study looked at a Rapiscan machine, which uses backscatter technology. These machines were used in many U.S. airports, but they have been replaced by new machines that uses a different detection technology, millimeter waves. The backscatter machines have been redeployed to jails, courthouses, cruise ships, and other settings.
Detection of Guns and Explosives
The researchers confirmed that the machine would detect casual attempts to smuggle guns or explosives through a checkpoint. A gun in the pocket or a big block of plastic explosives under the shirt would show up on the scanner.
Unfortunately it proved possible for a more clever attacker to carry a gun or explosives undetectably. To understand why, let’s review how the machines work. They produce a grayscale image of the front and rear of the subject seen from the front and rear. The background (i.e. where the body is not) is very dark, and the brightness of other materials depends on the atomic weight of the material.
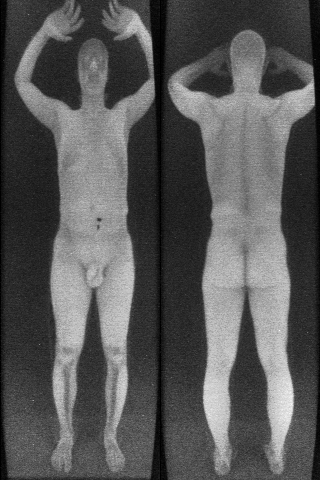
The bad news is that guns have high atomic weight, so they show up as very dark—the same color as the background. So a gun placed against the side of the body will look just like the background that one expects to see next to the body. Here’s a scan of a person with a pistol taped next to their knee.
The other bad news is that plastic explosives have almost exactly the same atomic weight as flesh, which means that explosives are the same color as flesh on the scans. (The researchers actually used a commercial simulant which is designed to look just like explosives on these scans, and is used for testing detectors.) Here’s a comparison: on the left a person with no explosives, on the right with about half a pound of explosive simulant taped to the belly. (The “navel” is really a metal detonator.)
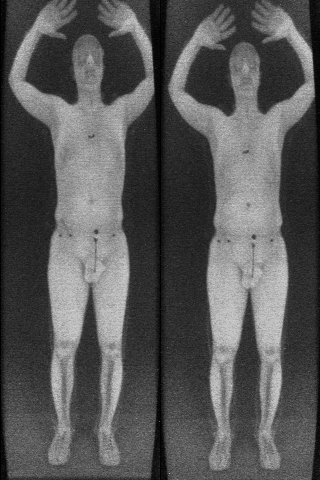
After passing through the security checkpoint, an attacker could remove and reshape the explosives and detonator.
Security and Policy Implications
The backscatter machines replaced the magnetometers (metal detectors) that were used previously. Compared to magnetometers, the backscatter machines were less effective at detecting guns—able to detect casually carried guns but missing side-positioned guns. However, the backscatter machines were better at detecting explosives—detecting casually carried explosives which the magnetometers would have missed. If you had to choose one or the other, the choice would depends on which attacks seemed more likely damaging.
A better option, from a security standpoint, would be to use both a magnetometer and a backscatter machine. Then you could detect all metal guns as well as casually carried explosives.
Significantly, the tricks shown above (side-carried gun and body-molded explosives) were described by previous researchers based on an understanding of the physics of backscatter. The researchers’ access to the machines allowed them to advance the public debate by confirming these attacks, but access was not required to figure out that the attacks were likely possible.
Although the backscatter machines are no longer used in U.S. airports, our security did rely on them for years, so it is useful to consider the wisdom of the decision to deploy them.
It’s possible that TSA knew about the machines’ flaws but decided to deploy them in place of the previous magnetometers anyway. This seems like a questionable security decision since the machines were expensive, privacy-invasive, and worse at detecting guns. A decision to use backscatter plus magnetometers would have been defensible from a security standpoint, but that option was not taken.
Or perhaps TSA did not know about the machines’ flaws, which reflects a lack of due diligence on their part. A decision this important and expensive should not have been made without considering the efficacy of the machines. The researchers present some evidence that pre-deployment testing was not thorough enough, but there is still a lot we don’t know.
My guess—and it’s only an educated guess—is that the truth lies somewhere in the middle, that TSA had evidence of the flaws but convinced themselves, with the help of the vendor, that they shouldn’t worry about the problems. Programs like this take on a momentum that can be difficult to stop, and TSA was under pressure to be seen changing to a higher-tech security approach.
Implications for Today’s Security
What does this mean for the security of the millimeter-wave machines used today? It’s hard to say. Some will probably argue that the deployment of millimeter-wave is evidence that it is probably better, but the same argument could have been made about backscatter—and we now know it would have been wrong.
My guess would be that millimeter-wave machines have their own vulnerabilities that are different. The researchers argue in their paper that the computer systems that operate the machines may have signficant security vulnerabilities, and it wouldn’t surprise me to learn that was the case.
The most important question—whether the new airport security regime makes us any safer than we were before—is still open.
We all know that installation of the Rapiscan was never about secuirity, it was about instlling an attitude of compliance with authority, to carry on a theatrics about security, and, above all in my opinion, to line Michael Chertoff’s pockets (http://www.motherjones.com/mojo/2010/01/airport-scanner-scam). In the intended sense, the Rapiscan was and is hugely successful. Evaluating it as a security measue only encourages the belief that it ever was intended as such, but it at least demonstrates positively that its effectiveness was a minor consideration.